产物拆包
一、认识
Webpack 默认会将尽可能多的模块代码打包在一起,一般来说,如果不对产物进行代码分割(或者拆包),全部打包到一个 chunk 中, 优点是能减少最终页面的 HTTP 请求数,但缺点也很明显:
-
页面初始代码包过大,影响首屏渲染性能。也就是说: 首屏加载的代码体积过大,即使是当前页面不需要的代码也会进行加载。
-
无法有效应用浏览器缓存,特别对于
NPM包这类变动较少的代码,业务代码哪怕改了一行都会导致NPM包缓存失效。也就是说: 线上缓存复用率极低,改动一行代码即可导致整个bundle产物缓存失效。
代码分离是 webpack 中最引人注目的特性之一。此特性能够把代码分离到不同的 bundle 中,然后可以按需加载或并行加载这些文件。代码分离可以用于获取更小的 bundle,以及控制资源加载优先级,如果使用合理,会极大影响加载时��间。有三种常用的代码分离方法:
-
入口起点:使用
entry配置手动地分离代码 -
动态导入:通过模块的内联函数调用来分离代码
-
防止重复:使用
SplitChunksPlugin去重和分离chunk
二、entry
webpack.config.js配置entry,配置如下所示:
const Path = require("path");
module.exports = {
mode: "production",
entry: {
entry1: Path.resolve(__dirname, "src", "entry1.js"),
entry2: Path.resolve(__dirname, "src", "entry2.js"),
},
output: {
filename: "[name].js",
path: Path.resolve(__dirname, "build"),
},
};
通过入口起点进行代码分离带来的问题:
- 如果入口 chunks 之间包含重复的模块,那些重复模块都会被引入到各个 bundle 中。
- 这种方法不够灵活,并且不能将核心应用程序逻辑进行动态拆分代码。
三、import
当涉及到动态代码拆分时,Webpack 提供了两个类似的技术。对于动态导入,
-
第一种、使用符合
ECMAScript提案的 import() 语法(优先选择): 以入口文件index.js引入lodash.js第三方模块、util.js本地模块为例:(async function () {
const {
default: { concat },
} = await import(/* webpackChunkName: "lodash" */ "lodash");
console.log(concat);
const { foo1 } = await import(/* webpackChunkName: "util" */ "./utils");
foo1();
})(); -
第二种、使用
webpack特定的require.ensure
四、SplitChunksPlugin
4.1 Chunk
Chunk 是 Webpack 内部一个非常重要的底层设计,用于组织、管理、优化最终产物,在构建流程进入生成(Seal)阶段后:
-
Webpack首先根据entry配置创建若干Chunk对象; -
遍历构建(
Make)阶段找到的所有Module对象,同一Entry下的模块分配到Entry对应的Chunk中 -
遇到异步模块则创建新的
Chunk对象,并将异步模块放入该Chunk -
分配完毕后,根据
SplitChunksPlugin的启发式算法进一步对这些Chunk执行裁剪、拆分、合并、代码调优,最终调整成运行性能(可能)更优的形态 -
最后,将这些
Chunk一个个输出成最终的产物(Asset)文件,编译工作到此结束
可以看出,Chunk 在构建流程中起着承上启下的关键作用 —— 一方面作为 Module 容器,根据一系列默认 分包策略 决定哪些模块应该合并在一起打包;另一方面根据 splitChunks 设定的策略优化分包,决定最终输出多少产物文件。
Chunk 分包结果的好坏直接影响了最终应用性能,Webpack 默认会将以下三种模块做分包处理:
-
Initial Chunk:entry模块及相应子模块打包成Initial Chunk; -
Async Chunk: 通过import('./xx')等语句导入的异步模块及相应子模块组成的Async Chunk; -
Runtime Chunk:运行时代码抽离成Runtime Chunk,可通过entry.runtime配置项实现。
Initial Chunk 与 Async Chunk 这种略显粗暴的规则会带来两个明显问题:
-
模块重复打包: 假如多个
Chunk同时依赖同一个Module,那么这个Module会被不受限制地重复打包进这些Chunk -
资源冗余 & 低效缓存:
Webpack会将Entry模块、异步模块所有代码都打进同一个单独的包,这在小型项目通常不会有明显的性能问题,但伴随着项目的推进,包体积逐步增长可能会导致应用的响应耗时越来越长。归根结底这种将所有资源打包成一个文件的方式存在两个弊端:-
资源冗余: 客户端必须等待整个应用的代码包都加载完毕才能启动运行,但可能用户当下访问的内容只需要使用其中一部分代码
-
缓存失效: 将所有资源达成一个包后,所有改动 —— 即使只是修改了一个字符,客户端都需要重新下载整个代码包,缓存命中率极低
-
这两个问题都可以通过更科学的分包策略解决,例如:
-
将被多个
Chunk依赖的包分离成独立Chunk,防止资源重复; -
node_modules中的资源通常变动较少,可以抽成一个独立的包,业务代码的频繁变动不会导致这部分第三方库资源缓存失效,被无意义地重复加载。
为此,Webpack 专门提供了 SplitChunksPlugin 插件,用于实现更灵活、可配置的分包,提升应用性能。
4.2 SplitChunksPlugin
SplitChunksPlugin 是 Webpack 4 之后内置实现的最新分包方案,与 Webpack3 时代的 CommonsChunkPlugin 相比,它能够基于一些更灵活、合理的启发式规则将 Module 编排进不同的 Chunk,最终构建出性能更佳,缓存更友好的应用产物。
SplitChunksPlugin 的用法比较抽象,算得上 Webpack 的一个难点,主要能力有:
-
SplitChunksPlugin支持根据Module路径、Module被引用次数、Chunk大小、Chunk请求数等决定是否对Chunk做进一步拆解,这些决策都可以通过optimization.splitChunks相应配置项调整定制,基于这些能力我们可以实现:-
单独打包某些特定路径的内容,例如
node_modules打包为vendors; -
单独打包使用频率较高的文件
-
-
SplitChunksPlugin还提供了optimization.splitChunks.cacheGroup概念,用于对不同特点的资源做分组处理,并为这些分组设置更有针对性的分包规则; -
SplitChunksPlugin还内置了default与defaultVendors两个cacheGroup,提供一些开箱即用的分包特性:-
node_modules资源会命中defaultVendors规则,并被单独打包; -
只有包体超过
20kb的Chunk才会被单独打包; -
加载
Async Chunk所需请求数不得超过30; -
加载
Initial Chunk所需请求数不得超过30
-
4.3 配置分包范围
首先,SplitChunksPlugin 默认情况下只对 Async Chunk 生效,我们可以通过 splitChunks.chunks 调整作用范围,该配置项支持如下值:
-
字符串
all:对Initial Chunk与Async Chunk都生效,建议优先使用该值; -
字符串
initial:只对Initial Chunk生效; -
字符串
async:只对Async Chunk生效; -
函数 (
chunk) =>boolean:该函数返回true时生效;
module.exports = {
//...
optimization: {
splitChunks: {
chunks: 'all',
},
},
}
设置为 all 效果最佳,此时 Initial Chunk、Async Chunk 都会被 SplitChunksPlugin 插件优化。
4.4 根据 Module 使用频率分包
SplitChunksPlugin 支持按 Module 被 Chunk 引用的次数决定是否分包,借助这种能力我们可以轻易将那些被频繁使用的模块打包成独立文件,减少代码重复。
用法很简单,只需用 splitChunks.minChunks 配置项设定最小引用次数,例如:
module.exports = {
//...
optimization: {
splitChunks: {
// 设定引用次数超过 2 的模块才进行分包
minChunks: 2
},
},
}
注意,这里被 Chunk 引用次数并不直接等价于被 import 的次数,而是取决于上游调用者是否被视作 Initial Chunk 或 Async Chunk 处理,例如:
// common.js
export default "common chunk";
// async-module.js
import common from './common'
// entry-a.js
import common from './common'
import('./async-module')
// entry-b.js
import common from './common'
其中,entry-a、entry-b 分别被视作 Initial Chunk 处理;async-module 被 entry-a 以异步方式引入,因此被视作 Async Chunk 处理。那么对于 common 模块来说,分别被三个不同的 Chunk 引入,此时引用次数为 3, 配合下面的配置:
// webpack.config.js
module.exports = {
entry: {
entry1: './src/entry-a.js',
entry2: './src/entry-b.js'
},
// ...
optimization: {
splitChunks: {
minChunks: 2,
//...
}
}
};
common 模块命中 optimization.splitChunks.minChunks = 2 规则,因此该模块可能会被单独分包,最终产物:
entry1.js
entry1.js
async-module.js
common.js
4.5 限制分包数量
在 minChunks 基础上,为防止最终产物文件数量过多导致 HTTP 网络请求数剧增,反而降低应用性能,Webpack 还提供了 maxInitialRequest/maxAsyncRequest 配置项,用于限制分包数量:
-
maxInitialRequest: 用于设置Initial Chunk最大并行请求数 -
maxAsyncRequests: 用于设置Async Chunk最大并行请求数
�这里所说的请求数,是指加载一个 Chunk 时所需要加载的所有分包数。例如对于一个 Chunk A,如果根据分包规则(如模块引用次数、第三方包)分离出了若干子 Chunk A[¡],那么加载 A 时,浏览器需要同时加载所有的 A[¡],此时并行请求数等于 ¡ 个分包加 A 主包,即 ¡+1。
举个例子,对于上例所说的模块关系:
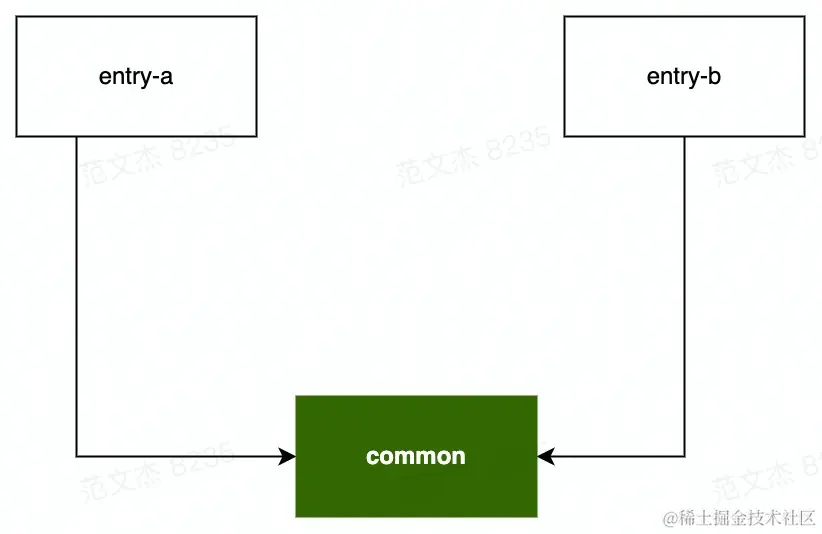
若 minChunks = 2 ,则 common 模块命中 minChunks 规则被独立分包,浏览器请求 entry-a 时,则需要同时请求 common 包,并行请求数为 1 + 1=2。
而对于下述模块关系:
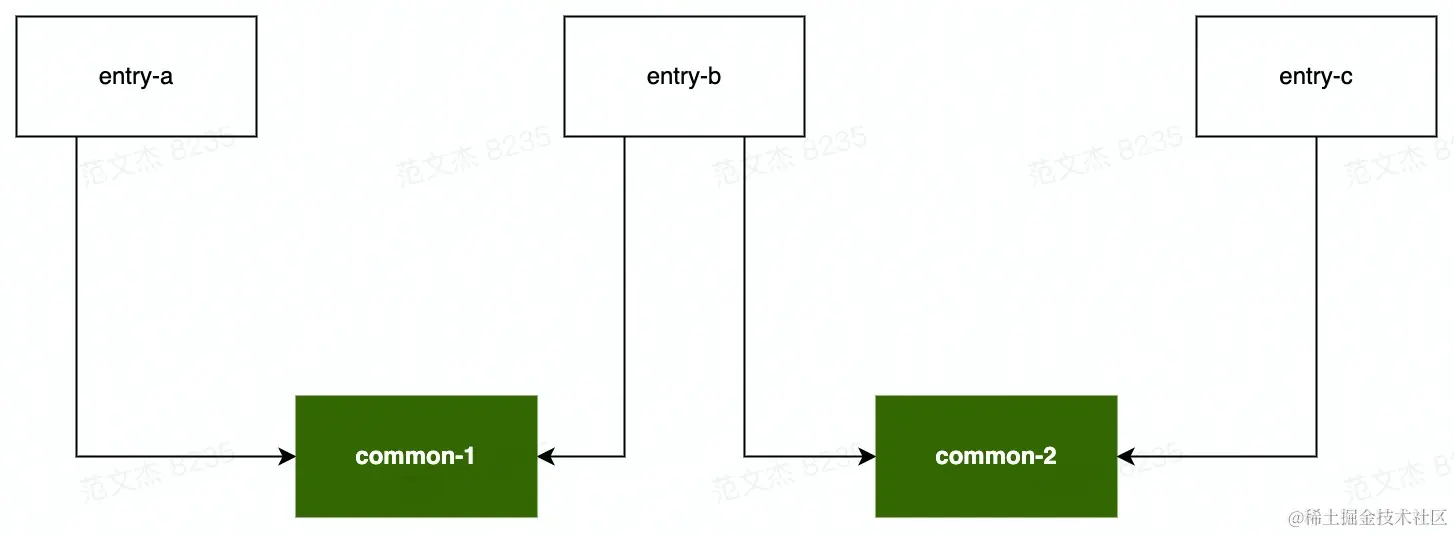
若 minChunks = 2 ,则 common-1 、common-2 同时命中 minChunks 规则被分别打包,浏览器请求 entry-b 时需要同时请求 common-1 、common-2 两个分包,并行数为 2 + 1 = 3,此时若 maxInitialRequest = 2,则分包数超过阈值,SplitChunksPlugin 会 放弃 common-1、common-2 中体积较小的分包。maxAsyncRequest 逻辑与此类似,不在赘述。
并行请求数关键逻辑总结如下:
-
Initial Chunk本身算一个请求 -
Async Chunk不算并行请求 -
通过
runtimeChunk拆分出的runtime不算并行请求 -
如果同时有两个
Chunk满足拆分规则,但是maxInitialRequests(或maxAsyncRequest) 的值只能允许再拆分一个模块,那么体积更大的模块会被优先拆解。
4.6 限制分包体积
除上面介绍的 minChunks —— ��模块被引用次数,以及 maxXXXRequest —— 包数量,这两个条件外,Webpack 还提供了一系列与 Chunk 大小有关的分包判定规则,借助这些规则我们可以实现当包体过小时直接取消分包 —— 防止产物过碎; 当包体过大时尝试对 Chunk 再做拆解 —— 避免单个 Chunk 过大。这一规则相关的配置项有:
-
minSize: 超过这个尺寸的Chunk才会正式被分包; -
maxSize: 超过这个尺寸的Chunk会尝试进一步拆分出更小的Chunk; -
maxAsyncSize: 与maxSize功能类似,但只对异步引入的模块生效 -
maxInitialSize: 与maxSize类似,但只对entry配置的入口模块生效; -
enforceSizeThreshold: 超过这个尺寸的Chunk会被强制分包,忽略上述其它Size限制。
那么,结合前面介绍的两种规则,SplitChunksPlugin 的主体流程如下:
-
SplitChunksPlugin尝试将命中minChunks规则的Module统一抽到一个额外的Chunk对象 -
判断该
Chunk是否满足maxInitialRequests阈值,若满足则进行下一步 -
判断该
Chunk资源的体积是否大于上述配置项minSize声明的下限阈值:-
如果体积小于
minSize则取消这次分包,对应的Module依然会被合并入原来的Chunk -
如果
Chunk体积大于minSize则判断是否超过maxSize�、maxAsyncSize、maxInitialSize声明的上限阈值,如果超过则尝试将该Chunk继续分割成更小的部分
-
提示:虽然 maxSize 等阈值规则会产生更多的包体,但缓存粒度会更小,命中率相对也会更高,配合持久缓存与 HTTP2 的多路复用能力,网络性能反而会有正向收益。
以上述模块关系为例:
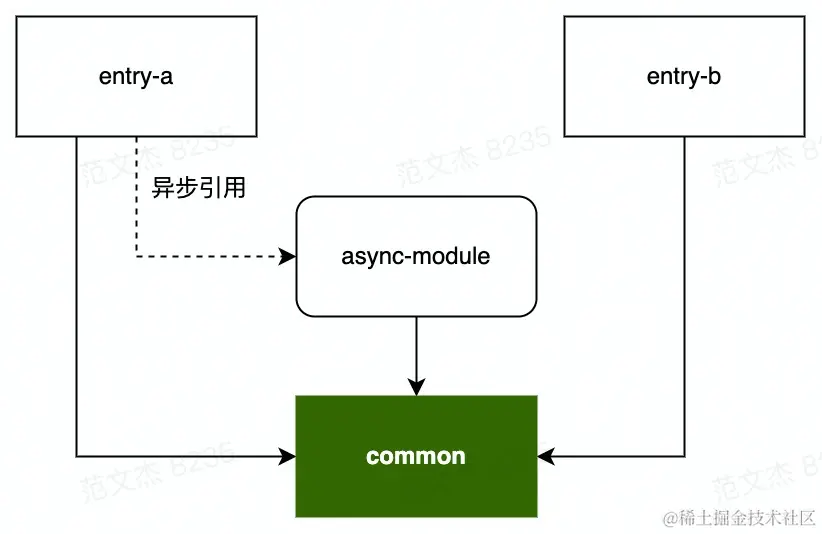
若此时 Webpack 配置的 minChunks 大于 2,且 maxInitialRequests 也同样大于 2,如果 common 模块的体积大于上述说明的 minxSize 配置项则分包成功,common 会被分离为单独的 Chunk,否则会被合并入原来的 3 个 Chunk。
注意: 这些条件的优先级顺序为: maxInitialRequest/maxAsyncRequests < maxSize < minSize。而命中 enforceSizeThreshold 阈值的 Chunk 会直接跳过这些条件判断,强制进行分包。
4.7 缓存组 cacheGroups
上述 minChunks、maxInitialRequest、minSize 都属于分包条件,决定是否对什么情况下对那些 Module 做分包处理。此外, SplitChunksPlugin 还提供了 cacheGroups 配置项用于为不同文件组设置不同的规则,例如:
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
vendors: {
test: /[\\/]node_modules[\\/]/,
minChunks: 1,
minSize: 0
}
},
},
},
};
示例通过 cacheGroups 属性设置 vendors 缓存组,所有命中 vendors.test 规则的模块都会被归类 vendors 分组,优先应用该组下的 minChunks、minSize 等分包配置。
cacheGroups 支持上述 minSize/minChunks/maxInitialRequest 等条件配置,此外还支持一些与分组逻辑强相关的属性,包括:
-
test: 接受正则表达式、函数及字符串,所有符合test判断的Module或Chunk都会被分到该组 -
type: 接受正则表达式、函数及字符串,与test类似均用于筛选分组命中的模块,区别是它判断的依据是文件类型而不是文件名,例如type = 'json'会命中所有JSON文件 -
idHint: 字符串型,用于设置Chunk ID,它还会被追加到最终产物文件名中,例如idHint = 'vendors'时,输出产物文件名形如vendors-xxx-xxx.js; -
priority: 数字型,用于设置该分组的优先级,若模块命中多个缓存组,则优先被分到priority更大的组
缓存组的作用在于能为不同类型的资源设置更具适用性的分包规则,一个典型场景是将所有 node_modules 下的模块统一打包到 vendors 产物,从而实现第三方库与业务代码的分离。
Webpack 提供了两个开箱即用的 cacheGroups,分别命名为 default 与 defaultVendors,默认配置:
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
default: {
idHint: "",
reuseExistingChunk: true,
minChunks: 2,
priority: -20
},
defaultVendors: {
idHint: "vendors",
reuseExistingChunk: true,
test: /[\\/]node_modules[\\/]/i,
priority: -10
}
},
},
},
};
这两个配置组能帮助我们:
-
将所有
node_modules中的资源单独打包到vendors-xxx-xx.js命名的产物 -
对引用次数大于等于
2的模块 —— 也就是被多个Chunk引用的模块,单独打包
开发者也可以将默认分组设置为 false,关闭分组配置,例如:
module.exports = {
//...
optimization: {
splitChunks: {
cacheGroups: {
default: false
},
},
},
};
4.8 SplitChunksPlugin 最佳实践
最后,我们再回顾一下 SplitChunksPlugin 支持的配置项:
-
minChunks: 用于设置引用阈值,被引用次数超过该阈值的Module才会进行分包处理 -
maxInitialRequest/maxAsyncRequests: 用于限制Initial Chunk(或Async Chunk) 最大并行请求数,本质上是在限制最终产生的分包数量; -
minSize: 超过这个尺寸的Chunk才会正式被分包 -
maxSize: 超过这个尺寸的Chunk会尝试继续做分包 -
maxAsyncSize: 与maxSize功能类似,但只对异步引��入的模块生效 -
maxInitialSize: 与maxSize类似,但只对entry配置的入口模块生效 -
enforceSizeThreshold: 超过这个尺寸的Chunk会被强制分包,忽略上述其它size限制; -
cacheGroups: 用于设置缓存组规则,为不同类型的资源设置更有针对性的分包策略
结合这些特性,业界已经总结了许多惯用的最佳分包策略,包括:
-
针对
node_modules资源: 可以将node_modules模块打包成单独文件(通过cacheGroups实现),防止业务代码的变更影响NPM包缓存,同时建议通过maxSize设定阈值,防止vendor包体过大;更激进的,如果生产环境已经部署HTTP2/3一类高性能网络协议,甚至可以考虑将每一个NPM包都打包成单独文件 -
针对业务代码: 设置
common分组,通过minChunks配置项将使用率较高的资源合并为Common资源; 首屏用不上的代码,尽量以异步方式引入; 设置optimization.runtimeChunk为true,将运行时代码拆分为独立资源;