认识
一、认识
React SSR 是一个结合SPA的SSR。通过 React SSR 渲染的页面, 需要再客户端激活才能实现交互。因此, React SSR 包含两部分: 服务端渲染的首屏、包含交互的SPA。也就是说: React SSR 首次渲染页面是服务端直出,后续的访问(路由切换、事件交互)都是SPA。这样一来,既能解决SEO问题,也能保持页面切换的效率,服务器的压力要比传统的SSR也相对小。
1.1 传统 React 渲染流程
-
浏览器发送请求
-
服务器返回
HTML -
浏览器发送
bundle.js请求 -
服务器返回
bundle.js -
浏览器执行
bundle.js中的React代码,将页面渲染出来
1.2 SSR React 渲染流程
-
浏览器发送请求
-
服务器运�行
React代码生成页面 -
服务器返回页面
二、模型
ReactSSR 的三体人模型:
- 服务端渲染:在服务端注入数据,构建出组件树
- 序列化成 HTML:脱水成人干
- 客户端渲染:到达客户端后泡水,激活水流,变回活人
2.1 喝水(render)
首先要有水可脱,所以先要拉取数据(水),在服务端完成组件首次渲染。也就是根据外部数据构建出初始组件树,过程中仅执行render及之前的几个生命周期,是为了尽可能缩短保命招数的前摇,尽快脱水
2.2 脱水(dehydrate)
简单理解: 接着对组件树进行脱水,使其在恶劣的环境同样能够以一种更简单的形态“生存”下来,比如禁用了JavaScript的客户端环境。比组件树更简单的形态是HTML片段,脱去生命的水气(动态数据),成为风干标本一样。内存里的组件树被序列化成了静态的HTML片段,还能看出来人样(初始视图),不过已经无法与之交互了,但这种便携的形态尤其适合运输,能够通过网络传输到地球上的某个客户端
实践理解: 在服务器端渲染时,首先服务端请求接口拿到数据,并处理准备好数据状态(如果使用 Redux,就是进行 store 的更新),为了减少客户端的请求,我们需要保留住这个状态。一般做法是在服务器端返回 HTML 字符串的时候,将数据 JSON.stringify 一并返回,这个过程,叫做脱水(dehydrate)
2.3 注水(hydrate)
简单理解: 抵达客户端后,如果环境适宜(没有禁用 JavaScript),就立即开始“浸泡”(hydrate),组件随之复苏。客户端“浸泡”的过程实际上是重新创建了组件树,将新生的水(state、props、context等)注入其中,并将鲜活的组件树塞进服务端渲染的干瘪躯壳里,使之复活:
浸泡也需要一定时间,所以在SSR模式下,客户端有一段时间是无法正常交互的,注水完成之后才能彻底复活(单向数据流和交互行为都恢复正常)
实践理解: 在客户端,就不再需要进行数据的请求了,可以直接使用服务端下发下来的数据,这个过程叫注水(hydrate)
三、工作流
SSR 会在服务端(这里主要指 Node.js 端)提前渲染出完整的 HTML 内容,那这是如何做到的呢?
首先需要保证前端的代码经过编译后放到服务端中能够正常执行,其次在服务端渲染前端组件,生成并组装应用的 HTML。这就涉及到 SSR 应用的两大生命周期: 构建时和运行时
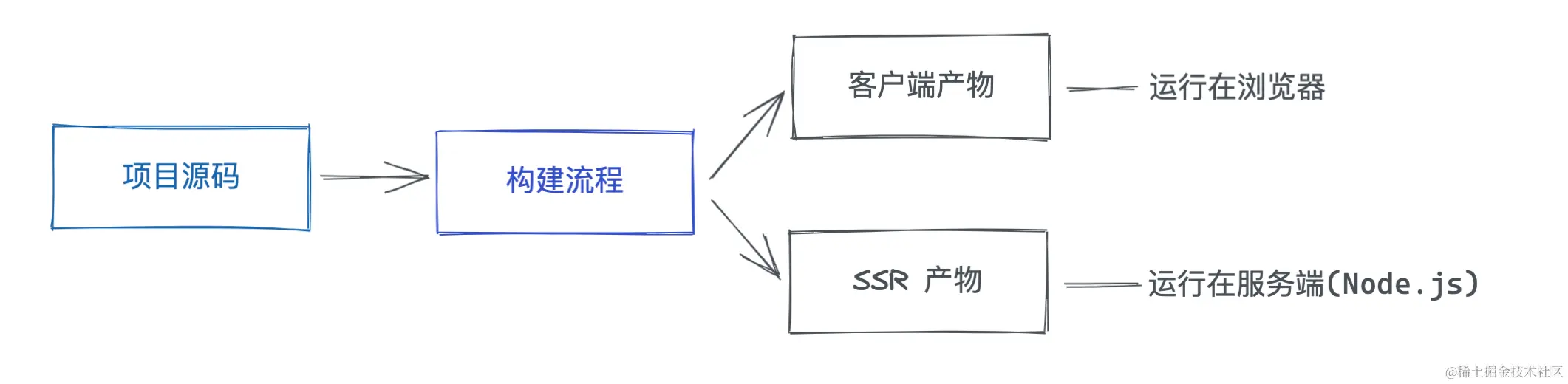
3.1 构建时
- 解决模块加载问题: 在原有的构建过程之外,需要加入
SSR构建的过程 ,具体来说,我们需要另外生成一份CommonJS格式的产物,使之能在Node.js正常加载。当然,随着Node.js本身对ESM的支持越来越成熟,我们也可以复用前端ESM格式的代码,Vite在开发阶段进行SSR构建也是这样的思路。
- 移除样式代码的引入: 直接引入一行
css在服务端其实是无法执行的,因为Node.js并不能解析CSS的内容。但CSS Modules的情况除外,如下所示:
import styles from './index.module.css'
// 这里的 styles 是一个对象,如{ "container": "xxx" },而不是 CSS 代码
console.log(styles)
- 依赖外部化(
external): 对于某些第三方依赖我们并不需要使用构建后的版本,而是直接从node_modules中读取,比如react-dom,这样在SSR构建的过程中将不会构建这些依赖,从而极大程度上加速SSR的构建。
3.2 运行时
对于 SSR 的运行时,一般可以拆分为比较固定的生命周期阶段,简单来讲可以整理为以下几个核心的阶段:

-
加载
SSR入口模块: 在这个阶段,我们需要确定SSR构建产物的入口,即组件的入口在哪里,并加载对应的模块 -
进行数据预取: 这时候
Node侧会通过查询数据库或者网络请求来获取应用所需的数据 -
渲染组件: 这个阶段为
SSR的核心,主要将第1步中加载的组件渲染成HTML字符串或者Stream流 -
HTML拼接: 在组件渲染完成之后,我们需要拼接完整的HTML字符串,并将其作为响应返回给浏览器
从上面的分析中你可以发现,SSR 其实是构建和运行时互相配合才能实现的,也就是说,仅靠构建工具是不够的
四、SSR API
React 提供的SSR API分为两部分,一部分面向服务端(react-dom/server),另一部分仍在客户端执行(react-dom)
4.1 ReactDOMServer
ReactDOMServer 相关 API 能够在服务端将 React 组件渲染成静态的 HTML 标签。 把组件渲染成 HTML 标签的工作在浏览器环境中也能完成,因此面向服务端的ReactDOMServer API 分为两类:
- 能跨Node.js、浏览器环境运行的
String API:renderToString()、renderToStaticMarkup() - 只能在Node.js 环境运行的
Stream API:renderToNodeStream()、renderToStaticNodeStream()
4.2 ReactDOMServer.renderToString
ReactDOMServer.renderToStaticMarkup(element)
最基础的SSR API, 输入React组件,输出HTML字符串。之后由客户端hydrate API对服务端返回的视图结构加上交互行为,完成页面渲染。
版本对比:
- React16之前:
renderToString() 基于字符串校验和的HTML节点复用方式,字对字的严格校验一致性,一旦发现不匹配就完全丢弃服务端渲染结果,在客户端渲染。
renderToString() 生成了大量的额外属性:
// renderToString
<div data-reactroot="" data-reactid="1"
data-react-checksum="122239856">
<!-- react-text: 2 -->This is some <!-- /react-text -->
<span data-reactid="3">server-generated</span>
<!-- react-text: 4--> <!-- /react-text -->
<span data-reactid="5">HTML.</span>
</div>
- React16之后:
renderToString() 采用单节点校验来复用服务端返回的HTML节点,不再生成data-reactid、data-react-checksum等体积占用大户。
renderToString()渲染结果:
// renderToString
<div data-reactroot="">
<!-- react-text: 2 -->This is some <!-- /react-text -->
<span>server-generated</span>
<!-- react-text: 4--> <!-- /react-text -->
<span>HTML.</span>
</div>
4.3 ReactDOMServer.renderToStaticMarkup
ReactDOMServer.renderToStaticMarkup(element)
同renderToString类似,区别在于API设计上,renderToStaticMarkup只用于纯展示(没有事件交互,不需要hydrate)的场景。因此renderToStaticMarkup只生成干净的HTML,不带额外的DOM属性(如 data-reactroot),响应体积上有些略微的优势。
renderToStaticMarkup() 渲染结果:
// renderToStaticMarkup
<div>
<span>server-generated</span>
<span>HTML.</span>
</div>
也就是说,目前React17 中,renderToStaticMarkup与renderToString的实际差异主要在于:
renderToStaticMarkup不生成data-reactrootrenderToStaticMarkup不在相邻文本节点之间生成<!-- -->。相当于合并了文本节点,不考虑节点复用,算是针对静态渲染的额外优化措施。
4.4 ReactDOMServer.renderToNodeStream
ReactDOMServer.renderToNodeStream(element)
对应于renderToString()的Stream API,将renderToString() 生成的HTML字符串以Node.js Readable stream形式返回。默认返回utf-8编码的字节流,其他编码格式需自行转换。另外,该 API 的实现依赖Node.js 的 Stream 特性 ,所以不能在浏览器环境使用。
4.5 ReactDOMServer.renderToStaticNodeStream
ReactDOMServer.renderToStaticNodeStream(element)
对应于renderToStaticMarkup的Stream API,将renderToStaticMarkup生成的干净HTML字符串以Node.js Readable stream形式返回。同样按utf-8编码,并且不能在浏览器环境使用。
4.6 ReactDOM.hydrate()
ReactDOM.hydrate(element, container[, callback])
hydrate配合SSR使用,与render()的区别在于渲染过程中能够复用服务端返回的现有HTML节点,只为其附加交互行为(事件监听等),并不重新创建DOM节点。
如果服务端返回的HTML与客户端渲染结果不一致时,出于性能考虑,hydrate() 并不纠正除文本节点外的SSR渲染结果,而是将错就错。
五、组件转换细节
服务端 React 组件是怎么变成HTML字符串的?
输入一个React组件:
class MyComponent extends React.Component {
constructor() {
super();
this.state = {
title: 'Welcome to React SSR!',
};
}
handleClick() {
alert('clicked');
}
render() {
return (
<div>
<h1 className="site-title" onClick={this.handleClick}>{this.state.title} Hello There!</h1>
</div>
);
}
}
经过ReactDOMServer.renderToString()处理后输出HTML字符串:
'<div data-reactroot=""><h1 class="site-title">Welcome to React SSR!<!-- --> Hello There!</h1></div>'
这中间发生了什么?
过程为创建组件示例、渲染组件、渲染DOM元素
5.1 创建组件
inst = new Component(element.props, publicContext, updater);
通过第三个参数updater注入了外部updater,用来拦截setState等操作:
var updater = {
isMounted: function (publicInstance) {
return false;
},
enqueueForceUpdate: function (publicInstance) {
if (queue === null) {
warnNoop(publicInstance, 'forceUpdate');
return null;
}
},
enqueueReplaceState: function (publicInstance, completeState) {
replace = true;
queue = [completeState];
},
enqueueSetState: function (publicInstance, currentPartialState) {
if (queue === null) {
warnNoop(publicInstance, 'setState');
return null;
}
queue.push(currentPartialState);
}
};
与先前维护虚拟 DOM 的方案相比,这种拦截状态更新的方式更快。
5.2 渲染组件
拿到初始数据(inst.state)后,依次执行组件生命周期函数:
// getDerivedStateFromProps
var partialState = Component.getDerivedStateFromProps.call(null, element.props, inst.state);
inst.state = _assign({}, inst.state, partialState);
// componentWillMount
if (typeof Component.getDerivedStateFromProps !== 'function') {
inst.componentWillMount();
}
// UNSAFE_componentWillMount
if (typeof inst.UNSAFE_componentWillMount === 'function' && typeof Component.getDerivedStateFromProps !== 'function') {
// In order to support react-lifecycles-compat polyfilled components,
// Unsafe lifecycles should not be invoked for any component with the new gDSFP.
inst.UNSAFE_componentWillMount();
}
注意新旧生命周期的互斥关系,优先getDerivedStateFromProps,若不存在才会执行componentWillMount/UNSAFE_componentWillMount,特殊的,如果这两个旧生命周期函数同时存在,会按以上顺序把两个函数都执行一遍.
接下来准备render了,但在此之前,先要检查updater队列,因为componentWillMount/UNSAFE_componentWillMount可能会引发状态更新:
if (queue.length) {
var nextState = oldReplace ? oldQueue[0] : inst.state;
for (var i = oldReplace ? 1 : 0; i < oldQueue.length; i++) {
var partial = oldQueue[i];
var _partialState = typeof partial === 'function' ? partial.call(inst, nextState, element.props, publicContext) : partial;
nextState = _assign({}, nextState, _partialState);
}
inst.state = nextState;
}
接着进入render:
child = inst.render();
并递归向下对子组件进行同样的处理(processChild):
while (React.isValidElement(child)) {
// Safe because we just checked it's an element.
var element = child;
var Component = element.type;
if (typeof Component !== 'function') {
break;
}
processChild(element, Component);
}
直至遇到原生 DOM 元素(组件类型不为function),将 DOM 元素“渲染”成字符串并输出:
if (typeof elementType === 'string') {
return this.renderDOM(nextElement, context, parentNamespace);
}
5.3 渲染DOM元素
特殊的,先对受控组件的props进行预处理:
// input
props = _assign({
type: undefined
}, props, {
defaultChecked: undefined,
defaultValue: undefined,
value: props.value != null ? props.value : props.defaultValue,
checked: props.checked != null ? props.checked : props.defaultChecked
});
// textarea
props = _assign({}, props, {
value: undefined,
children: '' + initialValue
});
// select
props = _assign({}, props, {
value: undefined
});
// option
props = _assign({
selected: undefined,
children: undefined
}, props, {
selected: selected,
children: optionChildren
});
接着正式开始拼接字符串,先创建开标签:
// 创建开标签
var out = createOpenTagMarkup(element.type, tag, props, namespace, this.makeStaticMarkup, this.stack.length === 1);
function createOpenTagMarkup(tagVerbatim, tagLowercase, props, namespace, makeStaticMarkup, isRootElement) {
var ret = '<' + tagVerbatim;
for (var propKey in props) {
var propValue = props[propKey];
// 序列化style值
if (propKey === STYLE) {
propValue = createMarkupForStyles(propValue);
}
// 创建标签属性
var markup = null;
markup = createMarkupForProperty(propKey, propValue);
// 拼上到开标签上
if (markup) {
ret += ' ' + markup;
}
}
// renderToStaticMarkup() 直接返回干净的HTML标签
if (makeStaticMarkup) {
return ret;
}
// renderToString() 给根元素添上额外的react属性 data-reactroot=""
if (isRootElement) {
ret += ' ' + createMarkupForRoot();
}
return ret;
}
再创建闭标签:
// 创建闭标签
var footer = '';
if (omittedCloseTags.hasOwnProperty(tag)) {
out += '/>';
} else {
out += '>';
footer = '</' + element.type + '>';
}
并处理子节点:
// 文本子节点,直接拼到开标签上
var innerMarkup = getNonChildrenInnerMarkup(props);
if (innerMarkup != null) {
out += innerMarkup;
} else {
children = toArray(props.children);
}
// 非文本子节点,开标签输出(返回),闭标签入栈
var frame = {
domNamespace: getChildNamespace(parentNamespace, element.type),
type: tag,
children: children,
childIndex: 0,
context: context,
footer: footer
};
this.stack.push(frame);
return out;
注意: 此时完整的 HTML 片段虽然尚未渲染完成(子节点并未转出 HTML,所以闭标签也没办法拼上去),但开标签部分已经完全确定,可以输出给客户端了
六、生命周期细节
SSR模式下,服务端只执行3个生命周期函数:
-
constructor -
getDerivedStateFromProps/componentWillMount -
render
过程冲只执行render及之前的生命周期,其余任何生命周期函数在服务端都不执行。
七、流式发送细节
HTML字符串是如何通过边拼接边流式发送的?
如此这般,每趟只渲染一个节点,直到栈中没有待完成的渲染任务为止:
function read(bytes) {
try {
var out = [''];
while (out[0].length < bytes) {
if (this.stack.length === 0) {
break;
}
// 取栈顶的渲染任务
var frame = this.stack[this.stack.length - 1];
// 该节点下所有子节点都渲染完毕
if (frame.childIndex >= frame.children.length) {
var footer = frame.footer;
// 当前节点(的渲染任务)出栈
this.stack.pop();
// 拼上闭标签,当前节点打完收工
out[this.suspenseDepth] += footer;
continue;
}
// 每处理一个子节点,childIndex + 1
var child = frame.children[frame.childIndex++];
var outBuffer = '';
try {
// 渲染一个节点
outBuffer += this.render(child, frame.context, frame.domNamespace);
} catch (err) { /*...*/ }
out[this.suspenseDepth] += outBuffer;
}
return out[0];
} finally { /*...*/ }
}
这种细粒度的任务调度让流式边拼接��边发送成为了可能,与React Fiber 调度机制异曲同工,同样是小段任务,Fiber 调度基于时间,SSR 调度基于工作量(while (out[0].length < bytes))
按给定的目标工作量(bytes)一块一块地输出,这正是流的基本特性:
stream 是数据集合,与数组、字符串差不多。但 stream 不一次性访问全部数据,而是一部分一部分发送/接收(chunk 式的)
生产者的生产模式已经完全符合流的特性了,因此,只需要将其包装成 Readable Stream 即可:
function ReactMarkupReadableStream(element, makeStaticMarkup, options) {
var _this;
// 创建 Readable Stream
_this = _Readable.call(this, {}) || this;
// 直接使用 renderToString 的渲染逻辑
_this.partialRenderer = new ReactDOMServerRenderer(element, makeStaticMarkup, options);
return _this;
}
var _proto = ReactMarkupReadableStream.prototype;
// 重写 _read() 方法,每次读指定 size 的字符串
_proto._read = function _read(size) {
try {
this.push(this.partialRenderer.read(size));
} catch (err) {
this.destroy(err);
}
};
异常简单:
function renderToNodeStream(element, options) {
return new ReactMarkupReadableStream(element, false, options);
}
至于非流式 API,则是一次性读完(read(Infinity))
function renderToString(element, options) {
var renderer = new ReactDOMServerRenderer(element, false, options);
try {
var markup = renderer.read(Infinity);
return markup;
} finally {
renderer.destroy();
}
}
不支持Error Boundary和Portal
为了支持流式渲染,同时保持String API和Stream API输出内容的一致性,牺牲了会引发渲染回溯的两大特性:
- Error Bounndary: 能够捕获子孙组件的运行时错误,并渲染一个降级UI
- Portal: 能够将组件渲染到指定的任意DOM节点上,同时保留事件按钮组件层级冒泡
很容易理解,流式边渲染边响应,无法(回溯回去)修改已经发出去的内容,所以其他类似的场景也不支持,比如渲染过程中动态往head里插个style或script标签。
八、双端对比细节
如果非要在服务端和客户端分别渲染不同的内容,应该如何处理?
方案: 首先保证首次渲染内容一致,再根据服务端没有componentDidMount生命周期,所以通过在compoentntDidMount生命周期中更新一个状态即可。如下所示:
class MyComponent extends React.Component {
state = {
isClient: false
}
render() {
return this.state.isClient ? '渲染...客户端内容' : '渲染...服务端内容';
}
componentDidMount() {
this.setState({
isClient: true
});
}
}
hydrate 究竟做了什么?
组件在服务端被灌入数据,并“渲染”成 HTML 后,在客户端能够直接呈现出有意义的内容,但并不具备交互行为,因为上面的服务端渲染过程并没有处理onClick等属性(其实是故意忽略了这些属性):
function shouldIgnoreAttribute(name, propertyInfo, isCustomComponentTag) {
if (name.length > 2 && (name[0] === 'o' || name[0] === 'O') && (name[1] === 'n' || name[1] === 'N')) {
return true;
}
}
也没有执行render之后的生命周期,组件没有被完整地“渲染”出来。因此,另一部分渲染工作仍然要在客户端完成,这个过程就是 hydrate.
- hydrate 与 render 的区别
hydrate()与render()拥有完全相同的函数签名,都能在指定容器节点上渲染组件:
ReactDOM.hydrate(element, container[, callback])
ReactDOM.render(element, container[, callback])
但不同于render()从零开始,hydrate()是发生在服务端渲染产物之上的,所以最大的区别是hydrate过程会复用服务端已经渲染好的 DOM 节点
- 节点复用策略
hydrate 模式下,组件渲染过程同样分为两个阶段:
- 第一阶段(render/reconciliation):找到可复用的现有节点,挂到fiber节点的stateNode上
- 第二阶段(commit):diffHydratedProperties决定是否需要更新现有节点,规则是看 DOM 节点上的attributes与props是否一致
也就是说,在对应位置找到一个“可能被复用的”(hydratable)现有 DOM 节点,暂时作为渲染结果记下,接着在 commit 阶段尝试复用该节点
选择现有节点具体如下:
// renderRoot的时候取第一个(可能被复用的)子节点
function updateHostRoot(current, workInProgress, renderLanes) {
var root = workInProgress.stateNode;
// hydrate模式下,从container中找出第一个可用子节点
if (root.hydrate && enterHydrationState(workInProgress)) {
var child = mountChildFibers(workInProgress, null, nextChildren, renderLanes);
workInProgress.child = child;
}
}
function enterHydrationState(fiber) {
var parentInstance = fiber.stateNode.containerInfo;
// 取第一个(可能被复用的)子节点,记到模块级全局变量上
nextHydratableInstance = getFirstHydratableChild(parentInstance);
hydrationParentFiber = fiber;
isHydrating = true;
return true;
}
选择标准是节点类型为元素节点(nodeType为1)或文本节点(nodeType为3):
// 找出兄弟节点中第一个元素节点或文本节点
function getNextHydratable(node) {
for (; node != null; node = node.nextSibling) {
var nodeType = node.nodeType;
if (nodeType === ELEMENT_NODE || nodeType === TEXT_NODE) {
break;
}
}
return node;
}
预选节点之后,渲染到原生组件(HostComponent)时,会将预选的节点挂到fiber节点的stateNode上:
// 遇到原生节点
function updateHostComponent(current, workInProgress, renderLanes) {
if (current === null) {
// 尝试复用预选的现有节点
tryToClaimNextHydratableInstance(workInProgress);
}
}
function tryToClaimNextHydratableInstance(fiber) {
// 取出预选的节点
var nextInstance = nextHydratableInstance;
// 尝试复用
tryHydrate(fiber, nextInstance);
}
以元素节点为例(文本节点与之类似):
function tryHydrate(fiber, nextInstance) {
var type = fiber.type;
// 判断预选节点是否匹配
var instance = canHydrateInstance(nextInstance, type);
// 如果预选的节点可复用,就挂到stateNode上,暂时作为渲染结果记下来
if (instance !== null) {
fiber.stateNode = instance;
return true;
}
}
注意,这里并不检查属性是否完全匹配,只要元素节点的标签名相同(如div、h1),就认为可复用:
function canHydrateInstance(instance, type, props) {
if (instance.nodeType !== ELEMENT_NODE || type.toLowerCase() !== instance.nodeName.toLowerCase()) {
return null;
}
return instance;
}
在第一阶段的收尾部分(completeWork)进行属性的一致性检查,而属性值纠错实际发生在第二阶段:
function completeWork(current, workInProgress, renderLanes) {
var _wasHydrated = popHydrationState(workInProgress);
// 如果存在匹配成功的现有节点
if (_wasHydrated) {
// 检查是否需要更新属性
if (prepareToHydrateHostInstance(workInProgress, rootContainerInstance, currentHostContext)) {
// 纠错动作放到第二阶段进行
markUpdate(workInProgress);
}
}
// 否则document.createElement创建节点
else {
var instance = createInstance(type, newProps, rootContainerInstance, currentHostContext, workInProgress);
appendAllChildren(instance, workInProgress, false, false);
workInProgress.stateNode = instance;
if (finalizeInitialChildren(instance, type, newProps, rootContainerInstance)) {
markUpdate(workInProgress);
}
}
}
一致性检查就是看 DOM 节点上的attributes与组件props是否一致,主要做 3 件事情:
- 文本子节点值不同报警告并纠错(用客户端状态修正服务端渲染结果)
- 其它style、class值等不同只警告,并不纠错
- DOM 节点上有多余的属性,也报警告
也就是说,只在文本子节点内容有差异时才会自动纠错,对于属性数量、值的差异只是抛出警告,并不纠正,因此,在开发阶段一定要重视渲染结果不匹配的警告
- 组件渲染流程
与render一样,hydrate也会执行完整的生命周期(包括在服务端执行过的前置��生命周期):
// 创建组件实例
var instance = new ctor(props, context);
// 执行前置生命周期函数
// ...getDerivedStateFromProps
// ...componentWillMount
// ...UNSAFE_componentWillMount
// render
nextChildren = instance.render();
// componentDidMount
instance.componentDidMount();
所以,单从客户端渲染性能上来看,hydrate与render的实际工作量相当,只是省去了创建DOM节点、设置初始属性值等工作
至此,React SSR 的下层实现全都浮出水面了