代码分割
一、背景
在生产环境下,为了提高页面加载性能,构建工具一般将项目的代码打包(bundle)到一起,这样上线之后只需要请求少量的 JS 文件,大大减少 HTTP 请求。当然,Vite 也不例外,默认情况下 Vite 利用底层打包引擎 Rollup 来完成项目的模块打包。
某种意义上来说,对线上环境进行项目打包是一个必须的操作。但随着前端工程的日渐复杂,单份的打包产物体积越来越庞大,会出现一系列应用加载性能问题,而代码分割可以很好地解决它们。
Code Splitting 解决的问题: 在传统的单 chunk 打包模式下,当项目代码越来越庞大,最后会导致浏览器下载一个巨大的文件,从页面加载性能的角度来说,主要会导致两个问题:
-
无法做到按需加载,即使是当前页面不需要的代码也会进行加载。
-
线上缓存复用率极低,改动一行代码即可导致整个
bundle产物缓存失效。
首先说第一个问题,一般而言,一个前端页面中的 JS 代码可以分为两个部分: Initital Chunk和Async Chunk,前者指页面首屏所需要的 JS 代码,而后者当前页面并不一定需要,一个典型的例子就是 路由组件,与当前路由无关的组件并不用加载。而项目被打包成单 bundle 之后,无论是Initial Chunk还是Async Chunk,都会打包进同一个产物,也就是说,浏览器加载产物代码的时候,会将两者一起加载,导致许多冗余的加载过程,从而影响页面性能。而通过Code Splitting我们可以将按需加载的代码拆分出单独的 chunk,这样应用在首屏加载时只需要加载Initial Chunk 即可,避免了冗余的加载过程,使页面性能得到提升。
其次,线上的缓存命中率是一个重要的性能衡量标准。对于线上站点而言,服务端一般在响应资源时加上一些 HTTP 响应头,最常见的响应头之一就是 cache-control,它可以指定浏览器的强缓存,比如设置为下面这样:
cache-control: max-age=31536000
表示资源过期时间为一年,在过期之前,访问相同的资源 url,浏览器直接利用本地的缓存,并不用给服务端发请求,这就大大降低了页面加载的网络开销。不过,在单 chunk 打包模式下面,一旦有一行代码变动,整个 chunk 的 url 地址都会变化,比如下图所示的场景:
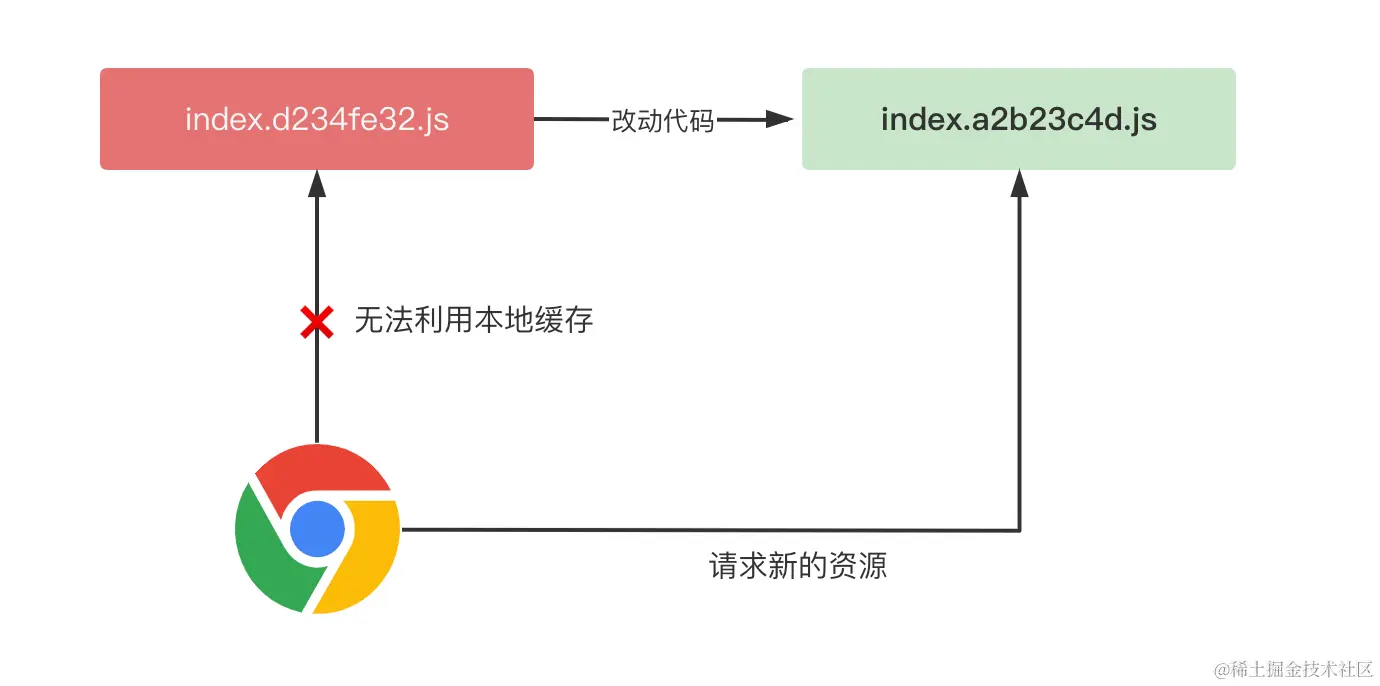
由于构建工具一般会根据产物的内容生成哈希值,一旦内容变化就会导致整个 chunk 产物的强缓存失效,所以单 chunk 打包模式下的缓存命中率极低,基本为零。
而进行Code Splitting之后,代码的改动只会影响部分的 chunk 哈希改动,如下图所示:

入口文件引用了A、B、C、D四个组件,当我们修改 A 的代码后,变动的 Chunk 就只有 A 以及依赖 A 的 Chunk 中,A 对应的 chunk 会变动,这很好理解,后者也会变动是因为相应的引入语句会变化,如这里的入口文件会发生如下内容变动:
import CompA from './A.d3e2f17a.js'
// 更新 import 语句
import CompA from './A.a5d2f82b.js'
也就是说,在改动 A 的代码后,B、C、D的 chunk 产物 url 并没有发生变化,从而可以让浏览器复用本地的强缓存,大大提升线上应用的加载性能。